AB实验系统
2025-02-24
AB实验系统的作用是通过不同的实验设计(A/B),通过一套具有数理逻辑理论基础的实验比对,帮助优化产品服务,通过不断对比迭代,来逐步提升关键指标(如转化率、留存率等)效果的系统,在互联网的系统推荐、活动营销、网站优化等场景被广泛使用。
业界实验系统的设计,通常会参考google的重叠实验系统架构设计的理论基础。 一套完整的实验系统,通常需要由实验分流体系和实验指标体系共同构成,实验分流体系用于指导实验流量的分配,实验指标体系用于评估对比不同实验组效果的好坏差异。
实验分层架构设计
一套完整的分层实验架构,通常由实验域、实验层、实验这3部份构成。
实验域(Domain)
实验域通常是指实验流量的一个划分,在一个完整业务场景中不同实验域的流量通常是相互隔离的。实验域中,只能包含实验层的结构。
实验层(Layer)
实验层分为了启动层(Launch Layer)和重叠层(Overlap Layer)。
启动层: 只包含实验(Experiment)。
重叠层: 只包含实验域(Domain)。
其中,不同实验层之间的流量是正交的。
实验(Experiment)
一个AB实验系统分层架构中的最小单元,通常需要包含一个对照组和多个实验组。对照组和不同实验组之间的流量是相互独立的。
实验系统通过这3个组成部分,便可以完成在线复杂的实验设计。我们以一个推荐系统中的召回层实验、精排层的实验为例,展开详细的设计描述,看看是如何通过上述的3个实验架构进行实验设计的:
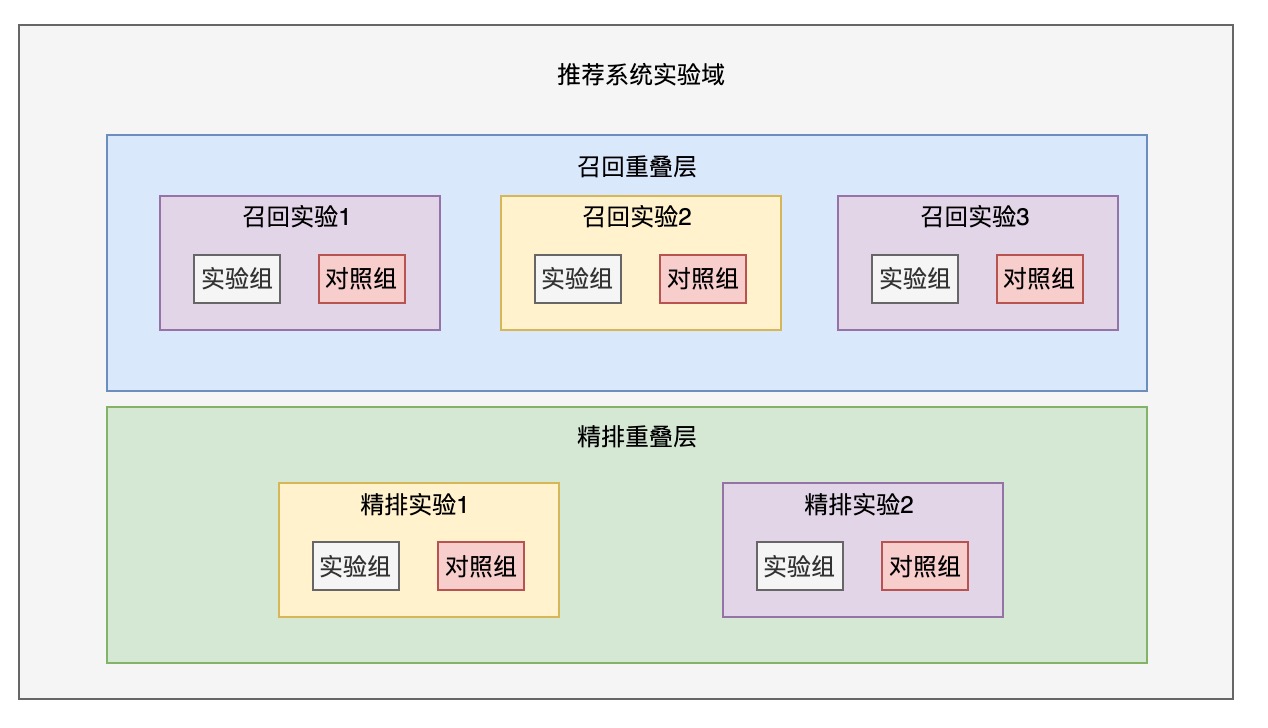
如上图所示,我们构建了一个推荐系统的实验域,在这个实验域之下,存在2个完全正交的召回重叠层和精排重叠层,这2个层的实验流量是正交的,保证了流量的复用性。 在同一个重叠层内,存在多个同步进行的实验,这些实验流量相互是隔离的,也保证了实验用户间不会产生相互干扰,数据指标统计也相互独立。
实验流量的正交和独立
为了保证上述的实验架构设计,需要有一套实验分桶算法来保证,同一个用户,在相同实验域的不同实验层之间的流量是正交的,同个实验层的不同实验组之间的流量是相互独立的,因此,衍生出了下面这种实验分桶的计算方式:
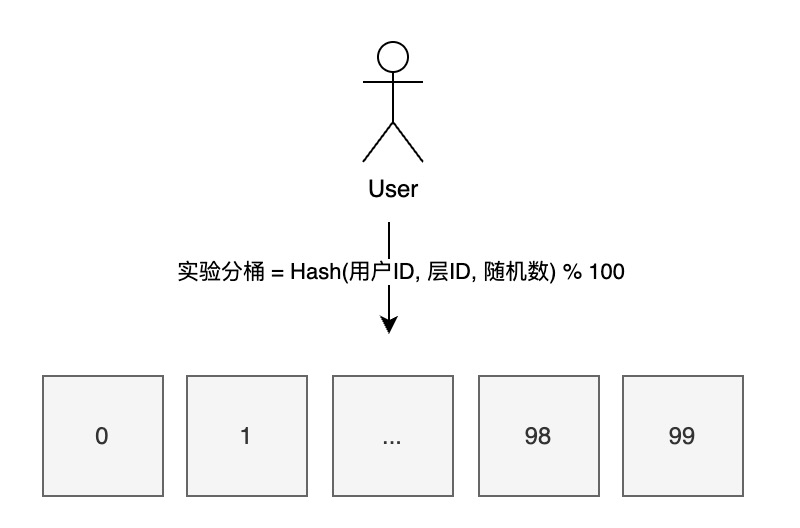
如上图所示,通常将一个层的实验流量等分为100个实验桶流量,每个实验桶流量包含了整个实验域1%的用户群体,不同实验层之间通过不同的层ID因子,来控制流量的正交性,相同实验层之间的不同实验组通过隔离不同的用户来达到流量的独立性, 以此来满足上述实验架构的正交和独立性原则。
实验分桶通常还会额外引入一个随机数的因子,通常这个因子会按天/周的维度进行变化,由此来达到重新打散相同实验层中人群分桶的目的, 防止有些特殊实验组和其他实验组效果差异过大后,分桶的人群大量流入/流出导致影响后续实验效果的情况。
实验指标体系建设
大数定律和中心极限定理
大数定律:样本均值收敛于期望值。
中心极限定理:大量独立同分布随机变量和的分布趋近于正态分布。
一二类实验错误
大数定律、中心极限定理和一二类实验错误的概念,奠定了实验系统的理论基础,下面我们将结合这些概念和实验系统的架构设计,来进行系统的设计说明。
原假设(H0): 通常指代的是实验提出的假设,通常需要给实验效果的好坏差异提出假设结论后,再通过反证法来证明实验的结果,因此需要在实验之前,先提出一个实验假设(既原假设)。
例如,我想证明实验组A的实验效果优于对照组的实验效果,那么,可以提出的原假设就是:
H0: 实验组相比于对照组的实验结果有明显的提升。
简单来说,我们实验的目的就是为了证明H0是否正确。 因此,我们需要通过一些实验数据进行计算来得出结论, 但由于通过数据计算得到的结论,可能和实际的结论还是有可能存在一定概率的偏差,我们将这种偏差称为一/二类实验错误,具体可以参考下面的表格说明:
| H0为真 | H0为假 | |
|---|---|---|
| 接受H0 | ☑️ | 一类实验错误(α) |
| 拒绝H0 | 二类实验错误(β) | ☑️ |
实验中,我们通常希望能够尽可能降低一二类实验错误发生的概率(尤其是一类实验错误),我们通常在接受H0的实验结论中,发生一类实验错误概率低于5%的情况,称为实验效果显著,低于1%的情况称为实验效果非常显著。
由于一二类实验错误的概率和实验的样本量有负相关关系,也就是说实验的样本量越大,发生一二类实验错误的概率越低, 所以,充足的实验样本量也是保证实验结论准确性的重要保证。
假设检验
假设检验是实验系统指标体系建设的核心理论基石。特定假设检验的方法会进行特定指标效果的验证,常见的几种假设检验方案,通常用以验证实验组之间的效果差异、指标和核心因素间的相关性等场景。
Z检验
用于检验AB实验中实验组和对照组是否存在效果差异的指标检验方法。z检验是实验系统中使用较为广泛的检验算法,用于对比检测不同实验组之间的效果差异,以此来验证原假设H0的正确性。在实验样本量比较小的情况下,会考虑使用t检验替代z检验。
F检验
用于检验AA实验中实验组和对照组是否存在效果差异的指标检验方法。通常用于对比两个完全相同的模型在不同实验组之间是否存在差异,以此来验证实验组之间的差异是可以忽略不计的,通常在实验系统刚刚完成搭建 或者 运行一些重要实验之前,会通过F检验来确保实验组之间是完全等价的。
卡方检验
用于独立性检验和拟合优度检验。通过比较观测频数(实际数据)与期望频数(理论数据)之间的数据差异来判断实验分组效果和变量之间的关系分布是否符合预期,以此判断实验效果和变量之间的独立性和相关性。
辛普森悖论
辛普森悖论(Simpson's Paradox)是统计学中的一种现象,指的是在分组数据中观察到的趋势与整体数据中观察到的趋势完全相反。这种悖论揭示了数据分析中一个重要的问题:当数据被细分为不同的子群体时,可能会得出与整体数据完全不同的结论。
我们以一组具体的实验数据为例,来具体的阐述这个问题:
| 实验组A | 曝光数 | 点击数 | 曝光点击率(CTR) |
|---|---|---|---|
| 用户A | 1000 | 150 | 15% |
| 用户B | 500 | 80 | 16% |
| 用户C | 300 | 60 | 20% |
| 用户D | 200 | 50 | 25% |
| 总计 | 2000 | 340 | 17% |
| 实验组B | 曝光数 | 点击数 | 曝光点击率(CTR) |
|---|---|---|---|
| 用户A | 500 | 65 | 13% |
| 用户B | 200 | 28 | 14% |
| 用户C | 400 | 72 | 18% |
| 用户D | 900 | 195 | 21.7% |
| 总计 | 2000 | 360 | 18% |
仔细分析上述2个实验组的数据,可以看到,在总曝光数不变的情况下,实验组B中的每个用户相比于实验组A,CTR数值都有明显的下降,但是总体统计得出的CTR数值却是实验组B更优于实验组A,这就是数据实验中产生的辛普森悖论。 究其根本原因,主要在于具体每个用户的曝光量产生了实际的变化, 实验组B中,将商品更多的曝光量向CTR更高的用户C和用户D进行了倾斜,所以导致了这样的统计结论的出现了。